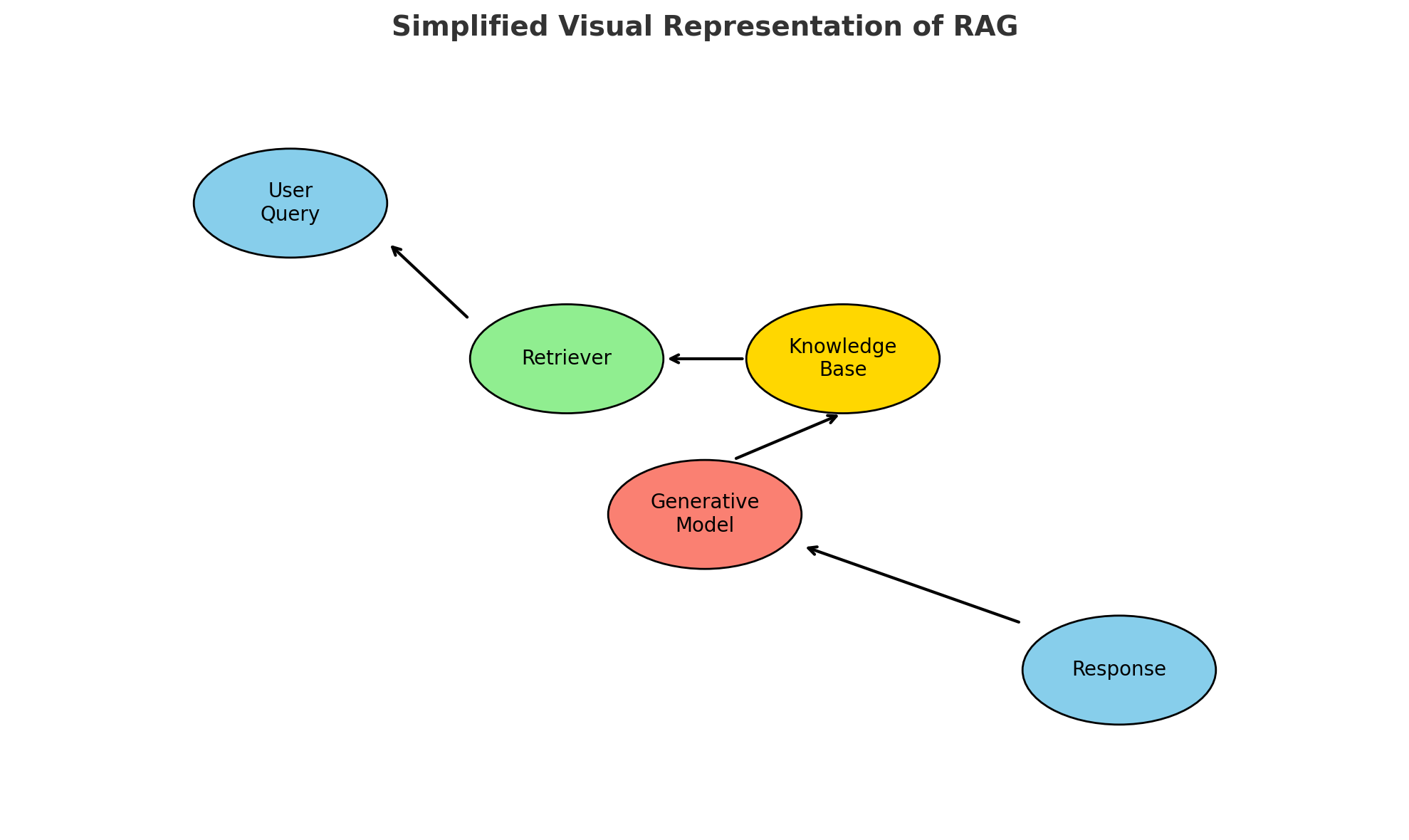
A retriever fetches relevant information or documents from a knowledge base, database, or external source.
The retriever typically uses techniques like vector search, dense retrieval (e.g., using embeddings from models like BERT), or traditional keyword-based search.
2. Augmentation
The retrieved information is fed into a generative model (e.g., GPT or similar language models).
The model uses this information to produce more accurate and contextually relevant responses.
3. Generation
The generative model synthesizes the input data (retrieved documents) and user query to generate an output.
RAG visual representation
Application RAG
Customer Support: Providing accurate answers based on company knowledge bases.
Legal/Medical Domains: Generating insights or advice from specialized, up-to-date knowledge.
Search Engines: Offering detailed, conversational answers rather than just links.
Education: Answering complex questions using curated academic resources.
Benefits of RAG
Dynamic Knowledge: Unlike standalone models that rely on static training data, RAG can integrate fresh and specific information at runtime.
Improved Accuracy: By grounding the responses in retrieved facts, the likelihood of generating hallucinated (incorrect) information is reduced.
Scalability: It can work with extensive external knowledge sources, enhancing the depth and breadth of response.
RAG is a powerful approach to leverage external knowledge effectively while maintaining the fluency and generative capabilities of large language models.